
A step-by-step process to use Google's Optical Character Recognition software that supports almost all major South Asian languages. Image by Subhashish Panigrahi, freely licensed under CC-by-SA 4.0.
The Optical Character Recognition (OCR) software by Google now works for more than 248 world languages, including all the major South Asian languages, and it's easy to use and works with over 90 percent accuracy for most languages.
OCR software has been extremely beneficial for the study of language, helping to extract text from images of virtually any printed text—and sometimes even handwriting, which opens the door to old texts, manuscripts, and more.
Ketan Pratap at NDTV Gadgets writes:
Users can start using the OCR capabilities in Drive by uploading scanned document in PDF or image form after which they can right-click on the document in Drive to open with Google Docs. After choosing the option, a document with the original image alongside extracted text opens, which can be edited. Google notes that users will not be required to specify the language of the document as the OCR in Drive will automatically determine it. The OCR capability in Google Drive is also available in Drive for Android.
On Twitter, many users have welcomed and even celebrated this new feature from Google:
Optical Character Recognition #OCR in Google Drive recongnizes many indic languages including #Kannada give it a try http://t.co/99UkCJQ6gb
— Omshivaprakash (@omshivaprakash) August 28, 2015
@shylobisnett if you have access to a scanner, you can do OCR through google drive. works a bit faster.
— Whet Moser (@whet) August 27, 2015
Wow. Searching Google Drive for a keyword also returns results for images containing that keyword in the image. Didn't realise it did OCR.
— Mark Osborne (@mosborne01) August 25, 2015
Typically OCR software has difficulty reading the text on old documents or pages with blemishes and ink marks, spitting out gibberish instead of legible text.
Google's support page on this project shares additional details about character formatting, like its ability to preserve bold and italicized fonts in the output text:
When processing your document, we attempt to preserve basic text formatting such as bold and italic text, font size and type, and line breaks. However, detecting these elements is difficult and we may not always succeed. Other text formatting and structuring elements such as bulleted and numbered lists, tables, text columns, and footnotes or endnotes are likely to get lost.
For some of the languages, like Malayalam and Tamil, the OCR works with almost 100 percent accuracy, and includes support for formatting things like like auto-cropping, separating text by discarding images, and ignoring color backgrounds, explains Tamil user and Wikimedian Ravishankar Ayyakkannu on Facebook:
[…] Google Tamil OCR works with 100% accuracy ! Keep testing with various samples and comment here. Performance has been the same for many other Indic languages too. […] Auto crops, discards images and colored background. Recognizes different layouts. I could find only 1 mistake in whole page. Testing latest Vikatan – https://docs.google.com/…/1OXre4…/edit.. […]
(Bangla, Malayalam, Kannada, Odia, Tamil, and Telugu-language users have commented in the same post with feedback after testing the updated OCR software. For a few scripts, like Gurmukhi (used to write Punjabi), it turns out that the output after OCR is quite poor, resulting largely in gibberish, when testing a screenshot image from Punjabi Wikipedia.)
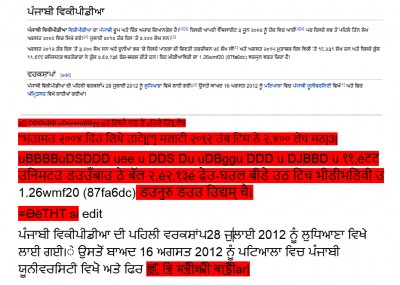
Issues with Gurmukhi script after OCR using Google's OCR. Screenshot from Punjabi Wikipedia.
This is quite a large leap for the languages with lots of old texts that are not yet digitized. Old and valuable texts in many languages could now be digitized and shared over the internet using platforms like Wikisource and could be preserved and made available for sharing knowledge.
Google's OCR partly uses Tesseract—an OCR engine released as freeware. Developed as a community project between 1995 and 2006 (and later taken over by Google), Tesseract is considered to be one of the world's most accurate OCR engines and works for over 60 languages. The source code is now hosted at https://github.com/tesseract-ocr. Check this link for the OCR outputs in various South Asian scripts.

This post is from Rising Voices, a Global Voices project that helps spread citizen media to places that don't normally have access to it. All Posts







5 comments
Does it work with Georgian?